Releases
Here is the list of official releases, however since it is early on in the development of libvirt, it is preferable when possible to just use the CVS version or snapshot, contact the mailing list and check the ChangeLog to gauge progresses.
0.2.2: Apr 17 2007
- Documentation: fix errors due to Amaya (with Simon Hernandez), virsh uses kB not bytes (Atsushi SAKAI), add command line help to qemud (Richard Jones), xenUnifiedRegister docs (Atsushi SAKAI), strings typos (Nikolay Sivov), ilocalization probalem raised by Thomas Canniot
- Bug fixes: virsh memory values test (Masayuki Sunou), operations without libvirt_qemud (Atsushi SAKAI), fix spec file (Florian La Roche, Jeremy Katz, Michael Schwendt), direct hypervisor call (Atsushi SAKAI), buffer overflow on qemu networking command (Daniel Berrange), buffer overflow in quemud (Daniel Berrange), virsh vcpupin bug (Masayuki Sunou), host PAE detections and strcuctures size (Richard Jones), Xen PAE flag handling (Daniel Berrange), bridged config configuration (Daniel Berrange), erroneous XEN_V2_OP_SETMAXMEM value (Masayuki Sunou), memory free error (Mark McLoughlin), set VIR_CONNECT_RO on read-only connections (S.Sakamoto), avoid memory explosion bug (Daniel Berrange), integer overflow for qemu CPU time (Daniel Berrange), QEMU binary path check (Daniel Berrange)
- Cleanups: remove some global variables (Jim Meyering), printf-style functions checks (Jim Meyering), better virsh error messages, increase compiler checkings and security (Daniel Berrange), virBufferGrow usage and docs, use calloc instead of malloc/memset, replace all sprintf by snprintf, avoid configure clobbering user's CTAGS (Jim Meyering), signal handler error cleanup (Richard Jones), iptables internal code claenup (Mark McLoughlin), unified Xen driver (Richard Jones), cleanup XPath libxml2 calls, IPTables rules tightening (Daniel Berrange),
- Improvements: more regression tests on XML (Daniel Berrange), Python bindings now generate exception in error cases (Richard Jones), Python bindings for vir*GetAutoStart (Daniel Berrange), handling of CD-Rom device without device name (Nobuhiro Itou), fix hypervisor call to work with Xen 3.0.5 (Daniel Berrange), DomainGetOSType for inactive domains (Daniel Berrange), multiple boot devices for HVM (Daniel Berrange),
- Various internal cleanups (Richard Jones,Daniel Berrange,Mark McLoughlin)
- Bug fixes: libvirt_qemud daemon path (Daniel Berrange), libvirt config directory (Daniel Berrange and Mark McLoughlin), memory leak in qemud (Mark), various fixes on network support (Mark), avoid Xen domain zombies on device hotplug errors (Daniel Berrange), various fixes on qemud (Mark), args parsing (Richard Jones), virsh -t argument (Saori Fukuta), avoid virsh crash on TAB key (Daniel Berrange), detect xend operation failures (Kazuki Mizushima), don't listen on null socket (Rich Jones), read-only socket cleanup (Rich Jones), use of vnc port 5900 (Nobuhiro Itou), assorted networking fixes (Daniel Berrange), shutoff and shutdown mismatches (Kazuki Mizushima), unlimited memory handling (Atsushi SAKAI), python binding fixes (Tatsuro Enokura)
- Build and portability fixes: IA64 fixes (Atsushi SAKAI), dependancies and build (Daniel Berrange), fix xend port detection (Daniel Berrange), icompile time warnings (Mark), avoid const related compiler warnings (Daniel Berrange), automated builds (Daniel Berrange), pointer/int mismatch (Richard Jones), configure time selection of drivers, libvirt spec hacking (Daniel Berrange)
- Add support for network autostart and init scripts (Mark McLoughlin)
- New API virConnectGetCapabilities() to detect the virtualization capabilities of a host (Richard Jones)
- Minor improvements: qemud signal handling (Mark), don't shutdown or reboot domain0 (Kazuki Mizushima), QEmu version autodetection (Daniel Berrange), network UUIDs (Mark), speed up UUID domain lookups (Tatsuro Enokura and Daniel Berrange), support for paused QEmu CPU (Daniel Berrange), keymap VNC attribute support (Takahashi Tomohiro and Daniel Berrange), maximum number of virtual CPU (Masayuki Sunou), virtsh --readonly option (Rich Jones), python bindings for new functions (Daniel Berrange)
- Documentation updates especially on the XML formats
- Various internal cleanups (Mark McLoughlin, Richard Jones, Daniel Berrange, Karel Zak)
- Bug fixes: avoid a crash in connect (Daniel Berrange), virsh args parsing (Richard Jones)
- Add support for QEmu and KVM virtualization (Daniel Berrange)
- Add support for network configuration (Mark McLoughlin)
- Minor improvements: regression testing (Daniel Berrange), localization string updates
- Finish XML <-> XM config files support
- Remove memory leak when freeing virConf objects
- Finishing inactive domain support (Daniel Berrange)
- Added a Relax-NG schemas to check XML instances
- more localizations
- bug fixes: VCPU info breakages on xen 3.0.3, xenDaemonListDomains buffer overflow (Daniel Berrange), reference count bug when creating Xen domains (Daniel Berrange).
- improvements: support graphic framebuffer for Xen paravirt (Daniel Berrange), VNC listen IP range support (Daniel Berrange), support for default Xen config files and inactive domains of 3.0.4 (Daniel Berrange).
- python bindings: release interpeter lock when calling C (Daniel Berrange)
- don't raise HTTP error when looking informations for a domain
- some refactoring to use the driver for all entry points
- better error reporting (Daniel Berrange)
- fix OS reporting when running as non-root
- provide XML parsing errors
- extension of the test framework (Daniel Berrange)
- fix the reconnect regression test
- python bindings: Domain instances now link to the Connect to avoid garbage collection and disconnect
- separate the notion of maximum memory and current use at the XML level
- Fix a memory leak (Daniel Berrange)
- add support for shareable drives
- add support for non-bridge style networking configs for guests(Daniel Berrange)
- python bindings: fix unsigned long marshalling (Daniel Berrange)
- new config APIs virConfNew() and virConfSetValue() to build configs from scratch
- hot plug device support based on Michel Ponceau patch
- added support for inactive domains, new APIs, various associated cleanup (Daniel Berrange)
- special device model for HVM guests (Daniel Berrange)
- add API to dump core of domains (but requires a patched xend)
- pygrub bootloader informations take over <os> informations
- updated the localization strings
- Bug for system with page size != 4k
- vcpu number initialization (Philippe Berthault)
- don't label crashed domains as shut off (Peter Vetere)
- fix virsh man page (Noriko Mizumoto)
- blktapdd support for alternate drivers like blktap (Daniel Berrange)
- memory leak fixes (xend interface and XML parsing) (Daniel Berrange)
- compile fix
- mlock/munlock size fixes (Daniel Berrange)
- improve error reporting
- fix a memory bug on getting vcpu informations from xend (Daniel Berrange)
- fix another problem in the hypercalls change in Xen changeset 86d26e6ec89b when getting domain informations (Daniel Berrange)
- Support for localization of strings using gettext (Daniel Berrange)
- Support for new Xen-3.0.3 cdrom and disk configuration (Daniel Berrange)
- Support for setting VNC port when creating domains with new xend config files (Daniel Berrange)
- Fix bug when running against xen-3.0.2 hypercalls (Jim Fehlig)
- Fix reconnection problem when talking directly to http xend
- Support for new hypercalls change in Xen changeset 86d26e6ec89b
- bug fixes: virParseUUID() was wrong, netwoking for paravirt guestsi (Daniel Berrange), virsh on non-existent domains (Daniel Berrange), string cast bug when handling error in python (Pete Vetere), HTTP 500 xend error code handling (Pete Vetere and Daniel Berrange)
- improvements: test suite for SEXPR <-> XML format conversions (Daniel Berrange), virsh output regression suite (Daniel Berrange), new environ variable VIRSH_DEFAULT_CONNECT_URI for the default URI when connecting (Daniel Berrange), graphical console support for paravirt guests (Jeremy Katz), parsing of simple Xen config files (with Daniel Berrange), early work on defined (not running) domains (Daniel Berrange), virsh output improvement (Daniel Berrange
- bug fixes: spec file fix (Mark McLoughlin), error report problem (with Hugh Brock), long integer in Python bindings (with Daniel Berrange), XML generation bug for CDRom (Daniel Berrange), bug whem using number() XPath function (Mark McLoughlin), fix python detection code, remove duplicate initialization errors (Daniel Berrange)
- improvements: UUID in XML description (Peter Vetere), proxy code cleanup, virtual CPU and affinity support + virsh support (Michel Ponceau, Philippe Berthault, Daniel Berrange), port and tty informations for console in XML (Daniel Berrange), added XML dump to driver and proxy support (Daniel Berrange), extention of boot options with support for floppy and cdrom (Daniel Berrange), features block in XML to report/ask PAE, ACPI, APIC for HVM domains (Daniel Berrange), fail saide-effect operations when using read-only connection, large improvements to test driver (Daniel Berrange)
- documentation: spelling (Daniel Berrange), test driver examples.
- bugfixes: build as non-root, fix xend access when root, handling of empty XML elements (Mark McLoughlin), XML serialization and parsing fixes (Mark McLoughlin), allow to create domains without disk (Mark McLoughlin),
- improvement: xenDaemonLookupByID from O(n^2) to O(n) (Daniel Berrange), support for fully virtualized guest (Jim Fehlig, DV, Mark McLoughlin)
- documentation: augmented to cover hvm domains
- headers include paths fixup
- proxy mechanism for unpriviledged read-only access by httpu
- building fixes: ncurses fallback (Jim Fehlig), VPATH builds (Daniel P. Berrange)
- driver cleanups: new entry points, cleanup of libvirt.c (with Daniel P. Berrange)
- Cope with API change introduced in Xen changeset 10277
- new test driver for regression checks (Daniel P. Berrange)
- improvements: added UUID to XML serialization, buffer usage (Karel Zak), --connect argument to virsh (Daniel P. Berrange),
- bug fixes: uninitialized memory access in error reporting, S-Expr parsing (Jim Fehlig, Jeremy Katz), virConnectOpen bug, remove a TODO in xs_internal.c
- documentation: Python examples (David Lutterkort), new Perl binding URL, man page update (Karel Zak)
- building fixes: --with-xen-distdir option (Ronald Aigner), out of tree build and pkginfo cflag fix (Daniel Berrange)
- enhancement and fixes of the XML description format (David Lutterkort and Jim Fehlig)
- new APIs: for Node information and Reboot
- internal code cleanup: refactoring internals into a driver model, more error handling, structure sharing, thread safety and ref counting
- bug fixes: error message (Jim Meyering), error allocation in virsh (Jim Meyering), virDomainLookupByID (Jim Fehlig),
- documentation: updates on architecture, and format, typo fix (Jim Meyering)
- bindings: exception handling in examples (Jim Meyering), perl ones out of tree (Daniel Berrange)
- virsh: more options, create, nodeinfo (Karel Zak), renaming of some options (Karel Zak), use stderr only for errors (Karel Zak), man page (Andrew Puch)
- add UUID lookup and extract API
- add error handling APIs both synchronous and asynchronous
- added minimal hook for error handling at the python level, improved the python bindings
- augment the documentation and tests to cover error handling
- Added XML description parsing, dependance to libxml2, implemented the creation API virDomainCreateLinux()
- new APIs to lookup and name domain by UUID
- fixed the XML dump when using the Xend access
- Fixed a few more problem related to the name change
- Adding regression tests in python and examples in C
- web site improvement, extended the documentation to cover the XML format and Python API
- Added devhelp help for Gnome/Gtk programmers
- Fix various bugs introduced in the name change
- Switch name from from 'libvir' to libvirt
- Starting infrastructure to add code examples
- Update of python bindings for completeness
- Update of the documentation, web site redesign (Diana Fong)
- integration of HTTP xend RPC based on libxend by Anthony Liquori for most operations
- Adding Save and Restore APIs
- extended the virsh command line tool (Karel Zak)
- remove xenstore transactions (Anthony Liguori)
- fix the Python bindings bug when domain and connections where freed
- First release
- Basic management of existing Xen domains
- Minimal autogenerated Python bindings
- a node is a single physical machine
- an hypervisor is a layer of software allowing to virtualize a node in a set of virtual machines with possibly different configurations than the node itself
- a domain is an instance of an operating system running on a virtualized machine provided by the hypervisor
- the API should not be targetted to a single virtualization environment though Xen is the current default, which also means that some very specific capabilities which are not generic enough may not be provided as libvirt APIs
- the API should allow to do efficiently and cleanly all the operations needed to manage domains on a node
- the API will not try to provide hight level multi-nodes management features like load balancing, though they could be implemented on top of libvirt
- stability of the API is a big concern, libvirt should isolate applications from the frequent changes expected at the lower level of the virtualization framework
- a connection to the Xen Daemon though an HTTP RPC layer
- a read/write connection to the Xen Store
- use Xen Hypervisor calls
- when used as non-root libvirt connect to a proxy daemon running as root and providing read-only support
- xend_internal: implements the driver functions though the Xen Daemon
- xs_internal: implements the subset of the driver availble though the Xen Store
- xen_internal: provide the implementation of the functions possible via direct hypervisor access
- proxy_internal: provide read-only Xen access via a proxy, the proxy code
is in the
proxy/directory. - xm_internal: provide support for Xen defined but not running domains.
- qemu_internal: implement the driver functions for QEmu and KVM virtualization engines. It also uses a qemud/ specific daemon which interracts with the QEmu process to implement libvirt API.
- test: this is a test driver useful for regression tests of the front-end part of libvirt.
- Normal paravirtualized Xen domains
- Fully virtualized Xen domains
- KVM domains
- Networking options for QEmu and KVM
- QEmu domains
- Discovering virtualization capabilities
0.2.1: Mar 16 2007
0.2.0: Feb 14 2007
0.1.11: Jan 22 2007
0.1.10: Dec 20 2006
0.1.9: Nov 29 2006
0.1.8: Oct 16 2006
0.1.7: Sep 29 2006
0.1.6: Sep 22 2006
0.1.5: Sep 5 2006
0.1.4: Aug 16 2006
0.1.3: Jul 11 2006
0.1.2: Jul 3 2006
0.1.1: Jun 21 2006
0.1.0: Apr 10 2006
0.0.6: Feb 28 2006
0.0.5: Feb 23 2006
0.0.4: Feb 10 2006
0.0.3: Feb 9 2006
0.0.2: Jan 29 2006
0.0.1: Dec 19 2005
Libvirt is a C toolkit to interact with the virtualization capabilities of recent versions of Linux (and other OSes), but libvirt won't try to provide all possible interfaces for interacting with the virtualization features.
To avoid ambiguity about the terms used here here are the definitions for some of the specific concepts used in libvirt documentation:
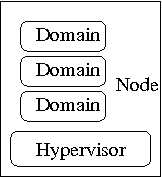
Now we can define the goal of libvirt: to provide the lowest possible generic and stable layer to manage domains on a node.
This implies the following:
So libvirt should be a building block for higher level management tools and for applications focusing on virtualization of a single node (the only exception being domain migration between node capabilities which may need to be added at the libvirt level). Where possible libvirt should be extendable to be able to provide the same API for remote nodes, however this is not the case at the moment, the code currently handle only local node accesses (extension for remote access support is being worked on, see the mailing list discussions about it).
Currently libvirt supports 2 kind of virtualization, and its internal structure is based on a driver model which simplifies adding new engines:
Libvirt Xen support
When running in a Xen environment, programs using libvirt have to execute in "Domain 0", which is the primary Linux OS loaded on the machine. That OS kernel provides most if not all of the actual drivers used by the set of domains. It also runs the Xen Store, a database of informations shared by the hypervisor, the kernels, the drivers and the xen daemon. Xend. The xen daemon supervise the control and execution of the sets of domains. The hypervisor, drivers, kernels and daemons communicate though a shared system bus implemented in the hypervisor. The figure below tries to provide a view of this environment:
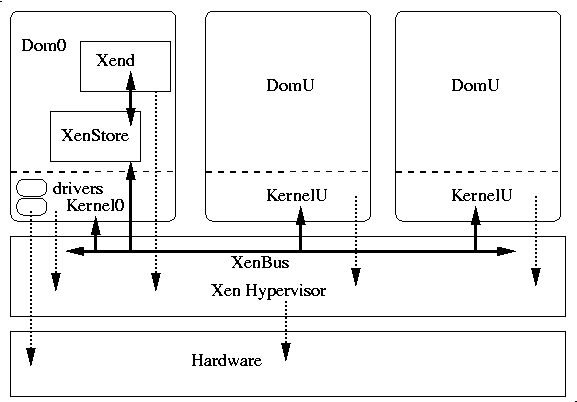
The library can be initialized in 2 ways depending on the level of priviledge of the embedding program. If it runs with root access, virConnectOpen() can be used, it will use three different ways to connect to the Xen infrastructure:
The library will usually interact with the Xen daemon for any operation changing the state of the system, but for performance and accuracy reasons may talk directly to the hypervisor when gathering state informations at least when possible (i.e. when the running program using libvirt has root priviledge access).
If it runs without root access virConnectOpenReadOnly() should be used to connect to initialize the library. It will then fork a libvirt_proxy program running as root and providing read_only access to the API, this is then only useful for reporting and monitoring.
Libvirt QEmu and KVM support
The model for QEmu and KVM is completely similar, basically KVM is based on QEmu for the process controlling a new domain, only small details differs between the two. In both case the libvirt API is provided by a controlling process forked by libvirt in the background and which launch and control the QEmu or KVM process. That program called libvirt_qemud talks though a specific protocol to the library, and connects to the console of the QEmu process in order to control and report on its status. Libvirt tries to expose all the emulations models of QEmu, the selection is done when creating the new domain, by specifying the architecture and machine type targetted.
The code controlling the QEmu process is available in the
qemud/ directory.
the driver based architecture
As the previous section explains, libvirt can communicate using different channels with the current hypervisor, and should also be able to use different kind of hypervisor. To simplify the internal design, code, ease maintainance and simplify the support of other virtualization engine the internals have been structured as one core component, the libvirt.c module acting as a front-end for the library API and a set of hypvisor drivers defining a common set of routines. That way the Xen Daemon accces, the Xen Store one, the Hypervisor hypercall are all isolated in separate C modules implementing at least a subset of the common operations defined by the drivers present in driver.h:
Note that a given driver may only implement a subset of those functions, (for example saving a Xen domain state to disk and restoring it is only possible though the Xen Daemon), in that case the driver entry points for unsupported functions are initialized to NULL.
The latest versions of libvirt can be found on the libvirt.org server ( HTTP, FTP). You will find there the released versions as well as snapshot tarballs updated from CVS head every hour
Anonymous CVS is also available, first register onto the server:
cvs -d :pserver:anoncvs@libvirt.org:2401/data/cvs login
it will request a password, enter anoncvs. Then you can checkout the development tree with:
cvs -d :pserver:anoncvs@libvirt.org:2401/data/cvs co
libvirt
Use ./autogen.sh to configure the local checkout, then make
and make install, as usual. All normal cvs commands are now
available except commiting to the base.
This section describes the XML format used to represent domains, there are variations on the format based on the kind of domains run and the options used to launch them:
The formats try as much as possible to follow the same structure and reuse elements and attributes where it makes sense.
Normal paravirtualized Xen guests:
The library use an XML format to describe domains, as input to virDomainCreateLinux()
and as the output of virDomainGetXMLDesc(),
the following is an example of the format as returned by the shell command
virsh xmldump fc4 , where fc4 was one of the running domains:
<domain type='xen' id='18'> <name>fc4</name> <os> <type>linux</type> <kernel>/boot/vmlinuz-2.6.15-1.43_FC5guest</kernel> <initrd>/boot/initrd-2.6.15-1.43_FC5guest.img</initrd> <root>/dev/sda1</root> <cmdline> ro selinux=0 3</cmdline> </os> <memory>131072</memory> <vcpu>1</vcpu> <devices> <disk type='file'> <source file='/u/fc4.img'/> <target dev='sda1'/> </disk> <interface type='bridge'> <source bridge='xenbr0'/> <mac address='aa:00:00:00:00:11'/> <script path='/etc/xen/scripts/vif-bridge'/> </interface> <console tty='/dev/pts/5'/> </devices> </domain>
The root element must be called domain with no namespace, the
type attribute indicates the kind of hypervisor used, 'xen' is
the default value. The id attribute gives the domain id at
runtime (not however that this may change, for example if the domain is saved
to disk and restored). The domain has a few children whose order is not
significant:
- name: the domain name, preferably ASCII based
- memory: the maximum memory allocated to the domain in kilobytes
- vcpu: the number of virtual cpu configured for the domain
- os: a block describing the Operating System, its content will be
dependant on the OS type
- type: indicate the OS type, always linux at this point
- kernel: path to the kernel on the Domain 0 filesystem
- initrd: an optional path for the init ramdisk on the Domain 0 filesystem
- cmdline: optional command line to the kernel
- root: the root filesystem from the guest viewpoint, it may be passed as part of the cmdline content too
- devices: a list of
disk,interfaceandconsoledescriptions in no special order
The format of the devices and their type may grow over time, but the following should be sufficient for basic use:
A disk device indicates a block device, it can have two
values for the type attribute either 'file' or 'block' corresponding to the 2
options availble at the Xen layer. It has two mandatory children, and one
optional one in no specific order:
- source with a file attribute containing the path in Domain 0 to the file or a dev attribute if using a block device, containing the device name ('hda5' or '/dev/hda5')
- target indicates in a dev attribute the device where it is mapped in the guest
- readonly an optional empty element indicating the device is read-only
An interface element describes a network device mapped on the
guest, it also has a type whose value is currently 'bridge', it also have a
number of children in no specific order:
- source: indicating the bridge name
- mac: the optional mac address provided in the address attribute
- ip: the optional IP address provided in the address attribute
- script: the script used to bridge the interfcae in the Domain 0
- target: and optional target indicating the device name.
A console element describes a serial console connection to
the guest. It has no children, and a single attribute tty which
provides the path to the Pseudo TTY on which the guest console can be
accessed
Life cycle actions for the domain can also be expressed in the XML format, they drive what should be happening if the domain crashes, is rebooted or is poweroff. There is various actions possible when this happen:
- destroy: The domain is cleaned up (that's the default normal processing in Xen)
- restart: A new domain is started in place of the old one with the same configuration parameters
- preserve: The domain will remain in memory until it is destroyed manually, it won't be running but allows for post-mortem debugging
- rename-restart: a variant of the previous one but where the old domain is renamed before being saved to allow a restart
The following could be used for a Xen production system:
<domain> ... <on_reboot>restart</on_reboot> <on_poweroff>destroy</on_poweroff> <on_crash>rename-restart</on_crash> ... </domain>
While the format may be extended in various ways as support for more hypervisor types and features are added, it is expected that this core subset will remain functional in spite of the evolution of the library.
Fully virtualized guests (added in 0.1.3):
Here is an example of a domain description used to start a fully virtualized (a.k.a. HVM) Xen domain. This requires hardware virtualization support at the processor level but allows to run unmodified operating systems:
<domain type='xen' id='3'>
<name>fv0</name>
<uuid>4dea22b31d52d8f32516782e98ab3fa0</uuid>
<os>
<type>hvm</type>
<loader>/usr/lib/xen/boot/hvmloader</loader>
<boot dev='hd'/>
</os>
<memory>524288</memory>
<vcpu>1</vcpu>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>restart</on_crash>
<features>
<pae/>
<acpi/>
<apic/>
</features>
<devices>
<emulator>/usr/lib/xen/bin/qemu-dm</emulator>
<interface type='bridge'>
<source bridge='xenbr0'/>
<mac address='00:16:3e:5d:c7:9e'/>
<script path='vif-bridge'/>
</interface>
<disk type='file'>
<source file='/root/fv0'/>
<target dev='hda'/>
</disk>
<disk type='file' device='cdrom'>
<source file='/root/fc5-x86_64-boot.iso'/>
<target dev='hdc'/>
<readonly/>
</disk>
<disk type='file' device='floppy'>
<source file='/root/fd.img'/>
<target dev='fda'/>
</disk>
<graphics type='vnc' port='5904'/>
</devices>
</domain>There is a few things to notice specifically for HVM domains:
- the optional
<features>block is used to enable certain guest CPU / system features. For HVM guests the following features are defined:pae- enable PAE memory addressingapic- enable IO APICacpi- enable ACPI bios
- the
<os>block description is very different, first it indicates that the type is 'hvm' for hardware virtualization, then instead of a kernel, boot and command line arguments, it points to an os boot loader which will extract the boot informations from the boot device specified in a separate boot element. Thedevattribute on theboottag can be one of:fd- boot from first floppy devicehd- boot from first harddisk devicecdrom- boot from first cdrom device
- the
<devices>section includes an emulator entry pointing to an additional program in charge of emulating the devices - the disk entry indicates in the dev target section that the emulation
for the drive is the first IDE disk device hda. The list of device names
supported is dependant on the Hypervisor, but for Xen it can be any IDE
device
hda-hdd, or a floppy devicefda,fdb. The<disk>element also supports a 'device' attribute to indicate what kinda of hardware to emulate. The following values are supported:floppy- a floppy disk controllerdisk- a generic hard drive (the default it omitted)cdrom- a CDROM device
hdcchannel, while for 3.0.3 and later, it can be emulated on any IDE channel. - the
<devices>section also include at least one entry for the graphic device used to render the os. Currently there is just 2 types possible 'vnc' or 'sdl'. If the type is 'vnc', then an additionalportattribute will be present indicating the TCP port on which the VNC server is accepting client connections.
It is likely that the HVM description gets additional optional elements and attributes as the support for fully virtualized domain expands, especially for the variety of devices emulated and the graphic support options offered.
KVM domain (added in 0.2.0)
Support for the KVM virtualization is provided in recent Linux kernels (2.6.20 and onward). This requires specific hardware with acceleration support and the availability of the special version of the QEmu binary. Since this relies on QEmu for the machine emulation like fully virtualized guests the XML description is quite similar, here is a simple example:
<domain type='kvm'> <name>demo2</name> <uuid>4dea24b3-1d52-d8f3-2516-782e98a23fa0</uuid> <memory>131072</memory> <vcpu>1</vcpu> <os> <type>hvm</type> </os> <devices> <emulator>/home/user/usr/kvm-devel/bin/qemu-system-x86_64</emulator> <disk type='file' device='disk'> <source file='/home/user/fedora/diskboot.img'/> <target dev='hda'/> </disk> <interface type='user'> <mac address='24:42:53:21:52:45'/> </interface> <graphics type='vnc' port='-1'/> </devices> </domain>
The specific points to note if using KVM are:
- the top level domain element carries a type of 'kvm'
- the <devices> emulator points to the special qemu binary required for KVM
- networking interface definitions definitions are somewhat different due to a different model from Xen see below
except those points the options should be quite similar to Xen HVM ones.
Networking options for QEmu and KVM (added in 0.2.0)
The networking support in the QEmu and KVM case is more flexible, and support a variety of options:
- Userspace SLIRP stack
Provides a virtual LAN with NAT to the outside world. The virtual network has DHCP & DNS services and will give the guest VM addresses starting from
10.0.2.15. The default router will be10.0.2.2and the DNS server will be10.0.2.3. This networking is the only option for unprivileged users who need their VMs to have outgoing access. Example configs are:<interface type='user'/>
<interface type='user'> <mac address="11:22:33:44:55:66:/> </interface> - Virtual network
Provides a virtual network using a bridge device in the host. Depending on the virtual network configuration, the network may be totally isolated,NAT'ing to aan explicit network device, or NAT'ing to the default route. DHCP and DNS are provided on the virtual network in all cases and the IP range can be determined by examining the virtual network config with '
virsh net-dumpxml <network name>'. There is one virtual network called'default' setup out of the box which does NAT'ing to the default route and has an IP range of192.168.22.0/255.255.255.0. Each guest will have an associated tun device created with a name of vnetN, which can also be overriden with the <target> element. Example configs are:<interface type='network'> <source network='default'/> </interface> <interface type='network'> <source network='default'/> <target dev='vnet7'/> <mac address="11:22:33:44:55:66:/> </interface> - Bridge to to LAN
Provides a bridge from the VM directly onto the LAN. This assumes there is a bridge device on the host which has one or more of the hosts physical NICs enslaved. The guest VM will have an associated tun device created with a name of vnetN, which can also be overriden with the <target> element. The tun device will be enslaved to the bridge. The IP range / network configuration is whatever is used on the LAN. This provides the guest VM full incoming & outgoing net access just like a physical machine. Examples include:
<interface type='bridge'> <source dev='br0'/> </interface> <interface type='bridge'> <source dev='br0'/> <target dev='vnet7'/> <mac address="11:22:33:44:55:66:/> </interface> <interface type='bridge'> <source dev='br0'/> <target dev='vnet7'/> <mac address="11:22:33:44:55:66:/> </interface> - Generic connection to LAN
Provides a means for the administrator to execute an arbitrary script to connect the guest's network to the LAN. The guest will have a tun device created with a name of vnetN, which can also be overriden with the <target> element. After creating the tun device a shell script will be run which is expected to do whatever host network integration is required. By default this script is called /etc/qemu-ifup but can be overriden.
<interface type='ethernet'/> <interface type='ethernet'> <target dev='vnet7'/> <script path='/etc/qemu-ifup-mynet'/> </interface>
- Multicast tunnel
A multicast group is setup to represent a virtual network. Any VMs whose network devices are in the same multicast group can talk to each other even across hosts. This mode is also available to unprivileged users. There is no default DNS or DHCP support and no outgoing network access. To provide outgoing network access, one of the VMs should have a 2nd NIC which is connected to one of the first 4 network types and do the appropriate routing. The multicast protocol is compatible with that used by user mode linux guests too. The source address used must be from the multicast address block.
<interface type='mcast'> <source address='230.0.0.1' port='5558'/> </interface>
- TCP tunnel
A TCP client/server architecture provides a virtual network. One VM provides the server end of the netowrk, all other VMS are configured as clients. All network traffic is routed between the VMs via the server. This mode is also available to unprivileged users. There is no default DNS or DHCP support and no outgoing network access. To provide outgoing network access, one of the VMs should have a 2nd NIC which is connected to one of the first 4 network types and do the appropriate routing.
Example server config:
<interface type='server'> <source address='192.168.0.1' port='5558'/> </interface>
Example client config:
<interface type='client'> <source address='192.168.0.1' port='5558'/> </interface>
To be noted, options 2, 3, 4 are also supported by Xen VMs, so it is possible to use these configs to have networking with both Xen & QEMU/KVMs connected to each other.
QEmu domain (added in 0.2.0)
Libvirt support for KVM and QEmu is the same code base with only minor changes. The configuration is as a result nearly identical, the only changes are related to QEmu ability to emulate various CPU type and hardware platforms, and kqemu support (QEmu own kernel accelerator when the emulated CPU is i686 as well as the target machine):
<domain type='qemu'> <name>QEmu-fedora-i686</name> <uuid>c7a5fdbd-cdaf-9455-926a-d65c16db1809</uuid> <memory>219200</memory> <currentMemory>219200</currentMemory> <vcpu>2</vcpu> <os> <type arch='i686' machine='pc'>hvm</type> <boot dev='cdrom'/> </os> <devices> <emulator>/usr/bin/qemu</emulator> <disk type='file' device='cdrom'> <source file='/home/user/boot.iso'/> <target dev='hdc'/> <readonly/> </disk> <disk type='file' device='disk'> <source file='/home/user/fedora.img'/> <target dev='hda'/> </disk> <interface type='network'> <source name='default'/> </interface> <graphics type='vnc' port='-1'/> </devices> </domain>
The difference here are:
- the value of type on top-level domain, it's 'qemu' or kqemu if asking for kernel assisted acceleration
- the os type block defines the architecture to be emulated, and optionally the machine type, see the discovery API below
- the emulator string must point to the right emulator for that architecture
Discovering virtualization capabilities (Added in 0.2.1)
As new virtualization engine support gets added to libvirt, and to handle cases like QEmu supporting a variety of emulations, a query interface has been added in 0.2.1 allowing to list the set of supported virtualization capabilities on the host:
char * virConnectGetCapabilities (virConnectPtr conn);
The value returned is an XML document listing the virtualization
capabilities of the host and virtualization engine to which
@conn is connected. One can test it using virsh
command line tool command 'capabilities', it dumps the XML
associated to the current connection. For example in the case of a 64 bits
machine with hardware virtualization capabilities enabled in the chip and
BIOS you will see
<capabilities> <host> <cpu> <arch>x86_64</arch> <features> <vmx/> </features> </cpu> </host> <!-- xen-3.0-x86_64 --> <guest> <os_type>xen</os_type> <arch name="x86_64"> <wordsize>64</wordsize> <domain type="xen"></domain> <emulator>/usr/lib64/xen/bin/qemu-dm</emulator> </arch> <features> </features> </guest> <!-- hvm-3.0-x86_32 --> <guest> <os_type>hvm</os_type> <arch name="i686"> <wordsize>32</wordsize> <domain type="xen"></domain> <emulator>/usr/lib/xen/bin/qemu-dm</emulator> <machine>pc</machine> <machine>isapc</machine> <loader>/usr/lib/xen/boot/hvmloader</loader> </arch> <features> </features> </guest> ... </capabilities>
The fist block (in red) indicates the host hardware capbilities, currently it is limited to the CPU properties but other information may be available, it shows the CPU architecture, and the features of the chip (the feature block is similar to what you will find in a Xen fully virtualized domain description).
The second block (in blue) indicates the paravirtualization support of the Xen support, you will see the os_type of xen to indicate a paravirtual kernel, then architecture informations and potential features.
The third block (in green) gives similar informations but when running a 32 bit OS fully virtualized with Xen using the hvm support.
This section is likely to be updated and augmented in the future, see the discussion which led to the capabilities format in the mailing-list archives.
main menu
related links
Graphics and design by Diana Fong